


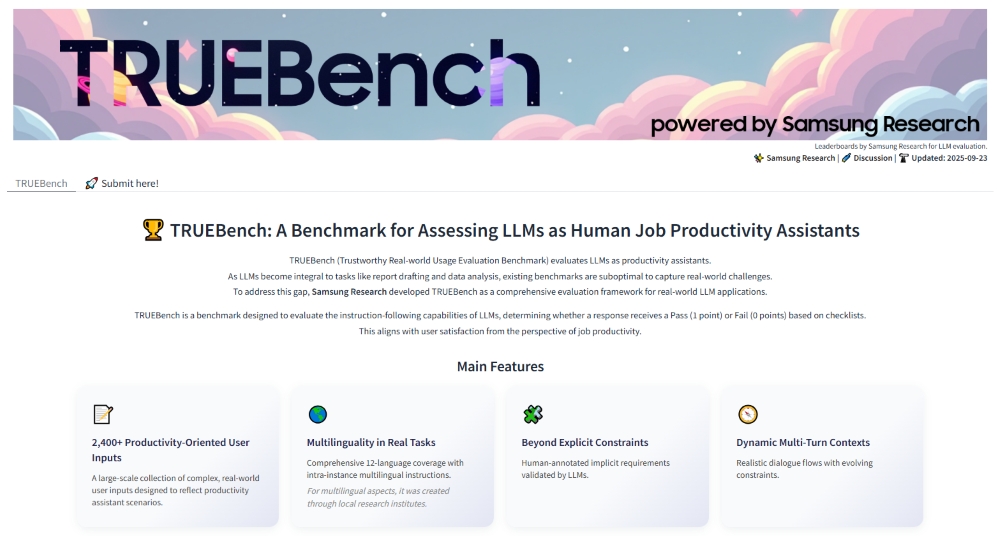
Samsung Electronics has introduced TRUEBench (Trustworthy Real-world Usage Evaluation Benchmark), a tool developed by Samsung Research to assess how large language models (LLMs) perform in workplace productivity scenarios. Unlike many existing benchmarks that mainly focus on English and single-turn question answering, TRUEBench is designed to reflect actual work environments. It covers 10 categories and 46 sub-categories across 12 languages, including multilingual and cross-linguistic situations.
The benchmark evaluates common enterprise tasks such as content generation, summarization, translation and data analysis. Test sets range from short prompts of a few characters to lengthy documents of over 20,000 characters, representing both simple and complex workplace needs. Evaluation is based on a collaborative process where humans first create criteria, AI systems review them, and humans refine them again. This ensures that scoring is consistent and less subjective while also accounting for implicit user needs.
TRUEBench includes 2,485 test sets and uses AI-powered automatic evaluation. Its datasets and leaderboards are available on Hugging Face, enabling researchers and organizations to compare multiple models for both performance and efficiency. This approach supports more realistic benchmarking of AI productivity tools.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave a comment